Character, by training:
Stupid Together.
- Dates
- Mar — Apr 2026
- Role
- Director · Solo
- Stack
- ComfyUI · LoRA · InstantID
- Base
- NoobAI XL vPred
- Format
- ~90 sec · 16 shots
The hard part of making an anime character consistent is not the drawing — it is making them the same person in every frame. That is what a LoRA is for. Not the style, not the scene: the continuity of the face.
01The film.
Stupid Together is a 90-second anime short about two friends arguing over the last cigarette in a pack. Rayana is a worn-down android: jet-black bob, red hoodie, mustard skull-and-bat print, fingerless gloves. Mai is a catgirl: auburn hair, slit pupils, navy bandana, a tail that does what it wants. They fight for it, street-fighter-style. Mai wins. Rayana cries. Mai shares it anyway.
The world is cyberpunk. The style is 90s OVA — halftone, heavy linework, cel shading, a limited palette. Neither character mentions being an android or a catgirl; the world is just the air they breathe. The film is about the cigarette.
I wrote it, directed it, trained the models, and ran every generation. Sixteen shots. Roughly ninety seconds.
02Before the scene, the dataset.
Character work starts with photographs. I took portraits of two people — clean lighting, neutral backgrounds, several angles each — and ran them through a ComfyUI pipeline pairing InstantID for face lock with a NoobAI XL checkpoint pushed toward cel shading. Each photo makes two passes: a low-denoise img2img to hold the bone structure, then a higher-denoise pass to coax out the halftone and the flattened palette of late-80s OVAs. ControlNet depth and openpose keep the composition honest.
The output of this stage is not a film. It is a dataset. Every image is hand-culled and captioned manually — automated captioning gets the clothes wrong and the era completely wrong, so every .txt is written by hand. The captions are what the LoRA will learn to respond to. Bad captions produce a character who does not remember her own outfit.
03Training the characters.
Two characters, two training runs, the same config. kohya_ss against NoobAI XL vPred: rank 16, alpha 8, AdamW8bit optimizer, cosine learning rate schedule, four epochs, batch size one. The finished LoRAs are r4yn_chr_v1 (Rayana) and m41_chr_v1 (Mai).
A third LoRA — a pre-built retro sci-fi style LoRA — carries the era. Identity and style travel separately. The checkpoint provides the rendering engine, the character LoRAs provide the people, the style LoRA provides the decade. They stack. The three-way weight balance is what you tune by hand until the character is recognizable, the style is correct, and the outfit is still there.
Identity and style travel separately. The checkpoint is the engine. The LoRA is the passenger.
04The generation pipeline.
Two workflows handle production. The solo workflow generates one character at a time — cleaner, faster, used for close-ups. The dual workflow uses regional prompting to place both characters in the same frame without cross-contamination: the model runs both LoRAs in series; the CLIP encoders run in parallel, one per character. Chaining CLIP in series was the first mistake. Cross-contamination means Rayana starts wearing Mai's clothes.
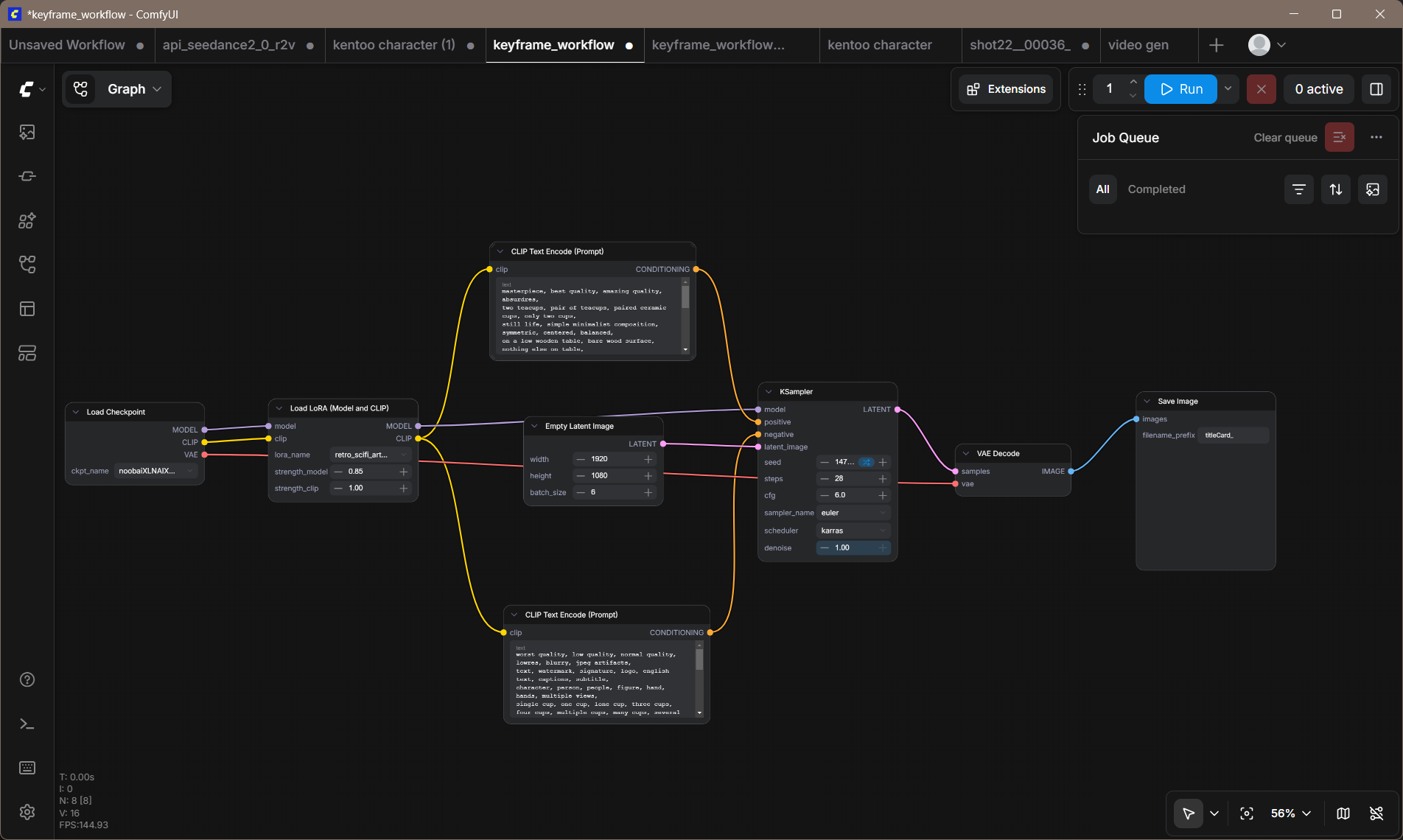
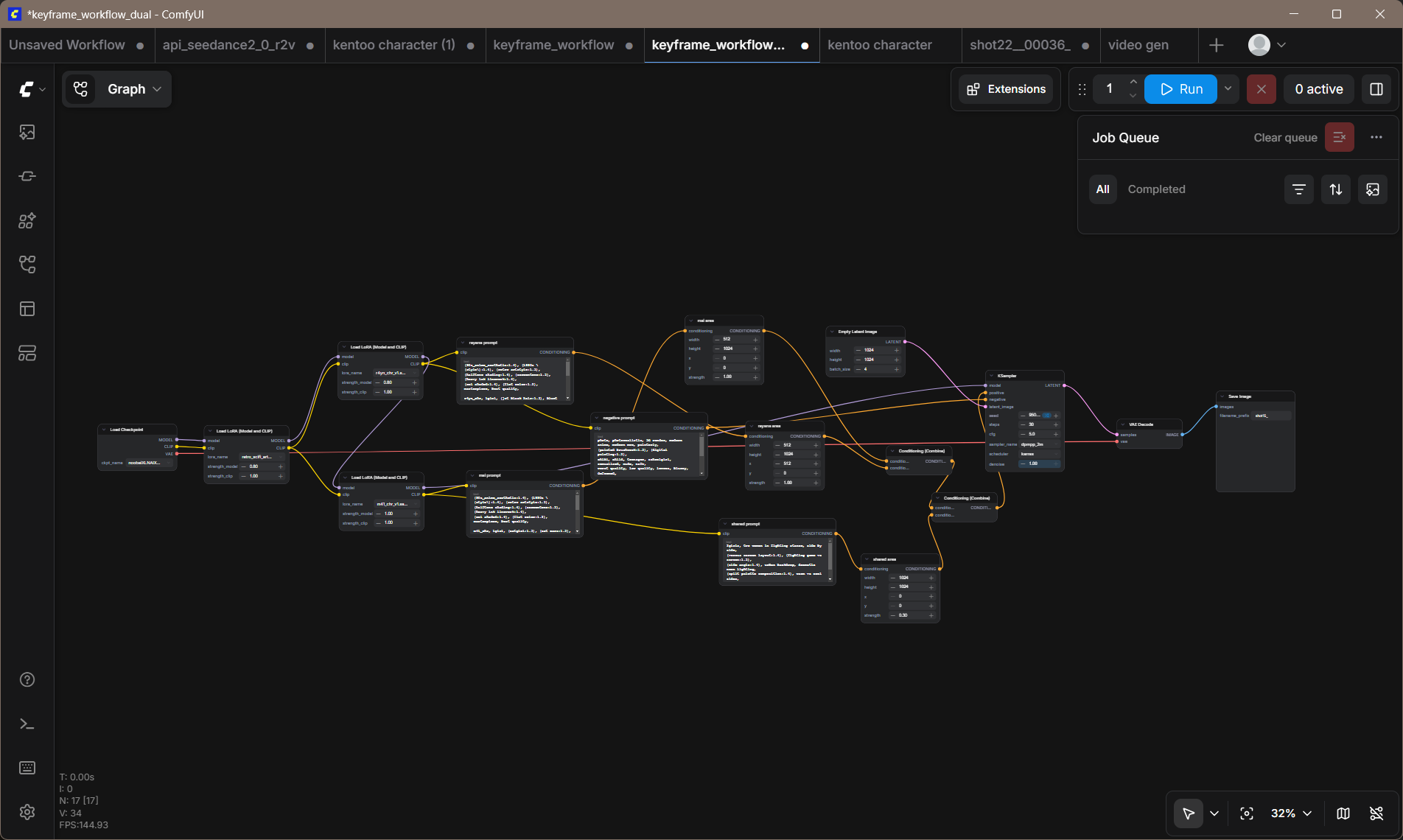
Keyframes render to 1024×1024 at 30 steps, cfg 5.0, dpmpp_2m karras. DaVinci Resolve scales them to a 1920×1080 timeline — a 1.875× upscale with about 24% top-and-bottom crop. Most subjects are centered in the generation, so the crop rarely cuts anything important. Hero shots get animated with WanVideo 2.1 I2V 14B — still frame in, two-second clip out — running on an RTX 3060 12GB at roughly two to three minutes per clip.
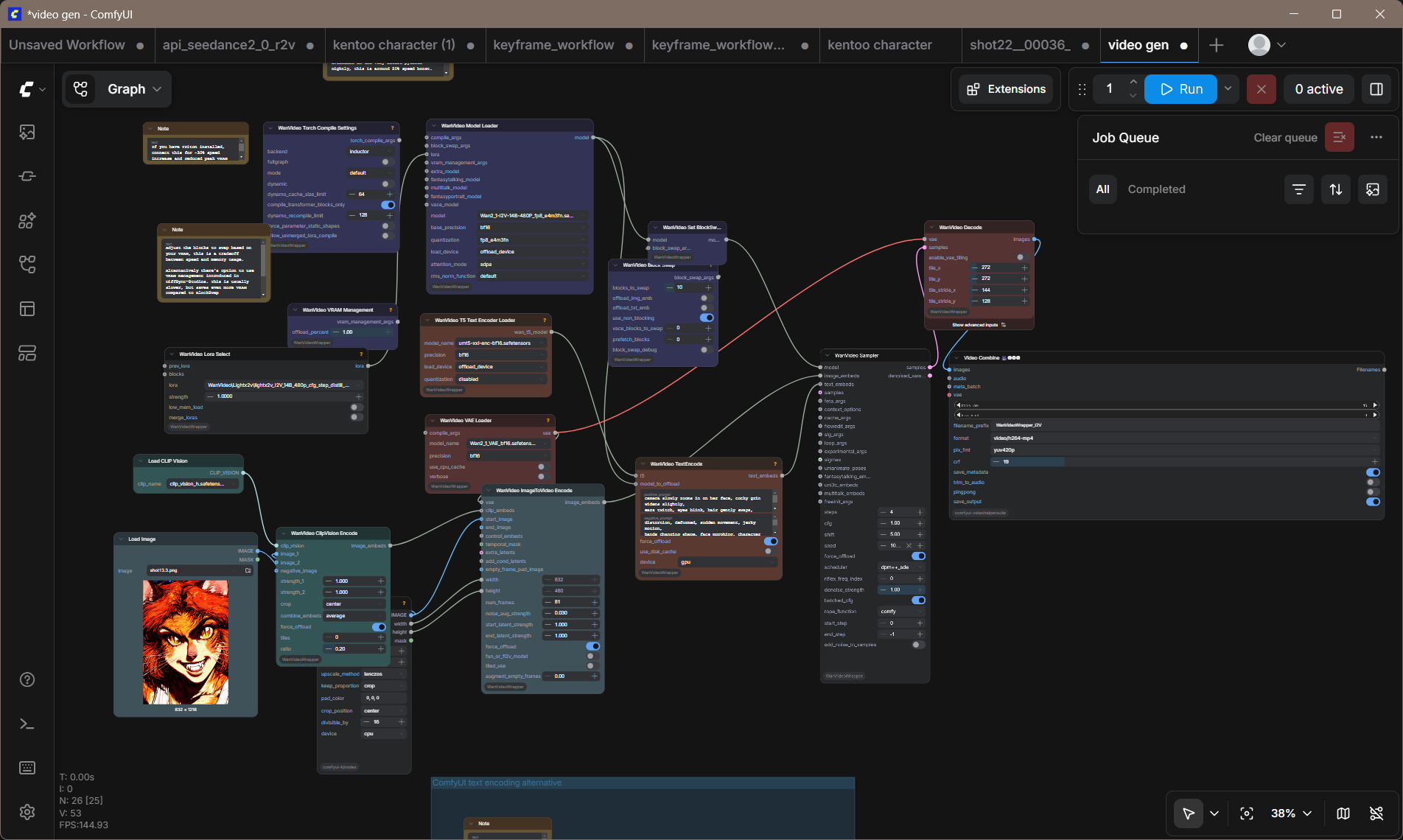
05What it's teaching me.
The biggest lesson is that prompt engineering for character consistency is not a writing problem — it is a vocabulary problem. The model knows what "fingerless gloves" means in a hundred different contexts; it needs weight on the specific context you want and negative weight on the contexts it defaults to. "Android damage" at high strength removes the outfit. At 0.7 it adds texture. There is a narrow register where the character is herself, and most of the work is finding it and writing it down so the next session can find it again.
The second lesson is that the hard shot is not the fight. The hard shot is the shared cigarette at the end — two characters, one frame, one hand holding out and the other taking. The model has strong opinions about what hands near each other should do, and those opinions are wrong in ways that are very difficult to describe in a negative prompt.
The third lesson is that the pipeline is not the film. Sixty rendered variants hand-culled down to sixteen keyframes — and what makes the cut is composition and expression, not render statistics. The best shot is almost never the one with the best technical output.
Directed and built solo, Atlanta, April 2026. Script, training configs, and ComfyUI workflows in the production folder. Editing and sound design in DaVinci Resolve.